Motivation

Instance segmentation is crucial for many manipulation policies that rely on object-centric reasoning (e.g. modeling an object’s pose or geometry). The appropriate segmentation varies depending on the task being performed; moving a clock, for example, would require a different segmen- tation compared to adjusting the hands of the clock.
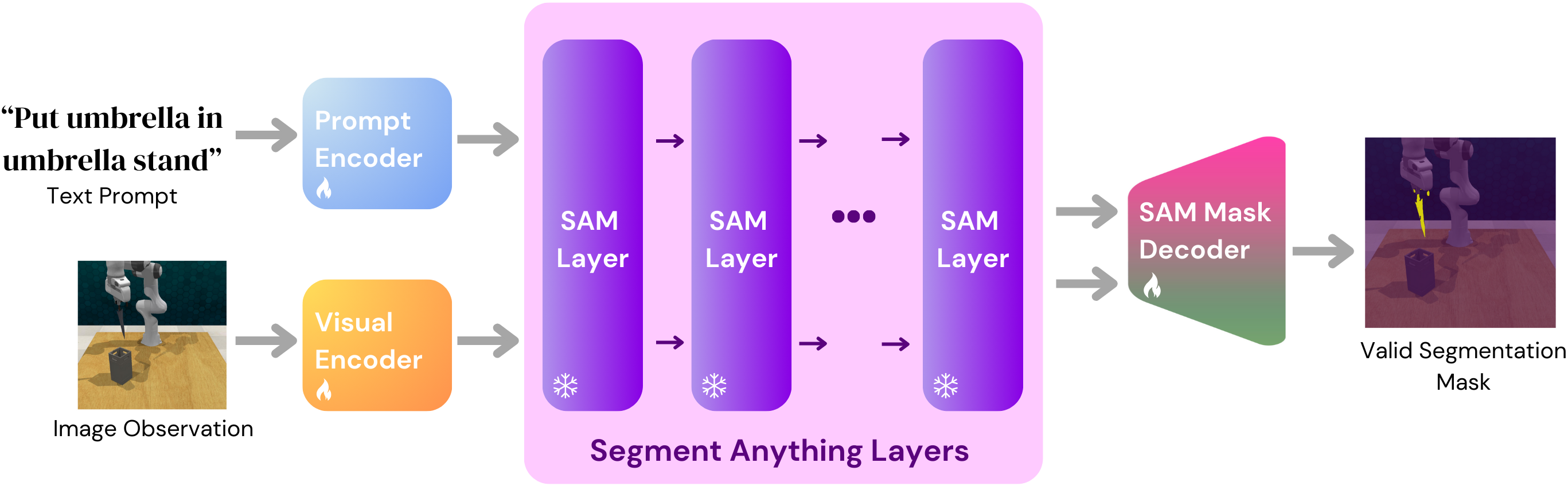
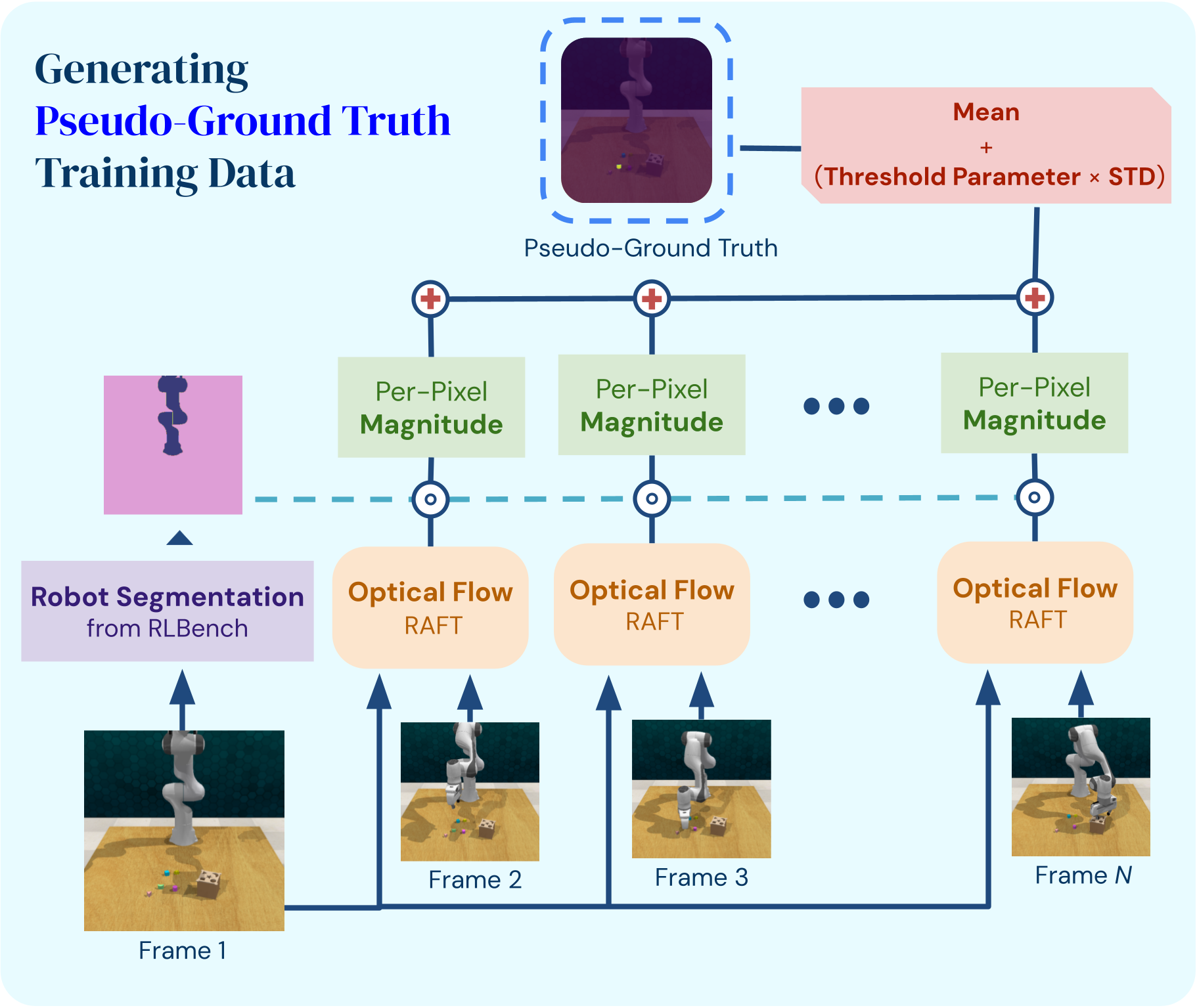
Obtaining sufficient annotated data to train task-specific segmentation models is generally infeasible; off-the-shelf foundation models, on the other hand, can perform poorly on out-of-distribution object instances or task descriptions. To address this issue, we propose TaskSeg, a novel system for the unsupervised learning of task-specific segmentations from unlabeled video demonstrations. We leverage the insight that in demonstra- tions used to train manipulation policies, the object being manipulated typically undergoes the most motion.
For an arbitrary object in an arbitrary task, we can extract pseudo- ground truth segmentations using optical flow, and finetune a foundation model for few shot object segmentation at policy deployment. We demonstrate our method’s ability to generate high-quality segmentations both on a suite of manipulation tasks in simulation and on human demonstrations collected in the real world.